— Runs every CLI worth running —



Run Claude, Codex, Gemini, and OpenCode in one terminal. Watch them collaborate in live tiles, benchmark the outputs, and ship the winner.
Warp bets on one cloud agent. iTerm2 adds a chat sidebar. Ghostty stays pure. None of them let you spawn Claude, Codex, Gemini and OpenCode side-by-side, watch them coordinate in a shared chat, score them against each other, and ship the winner. AnvilTerm does. It treats multi-agent as a first-class primitive — live tiles, MCP control plane, SwarmRoom, Arena, Forge marketplace — not a feature on the roadmap.
Watching one AI work is productivity.
Watching four of them compete for your prompt is the future.
The open-source AnvilTerm stays MIT-licensed on GitHub, forever. AnvilTerm Pro is the customized studio build we use ourselves — the same agents, with an entire production suite around them.
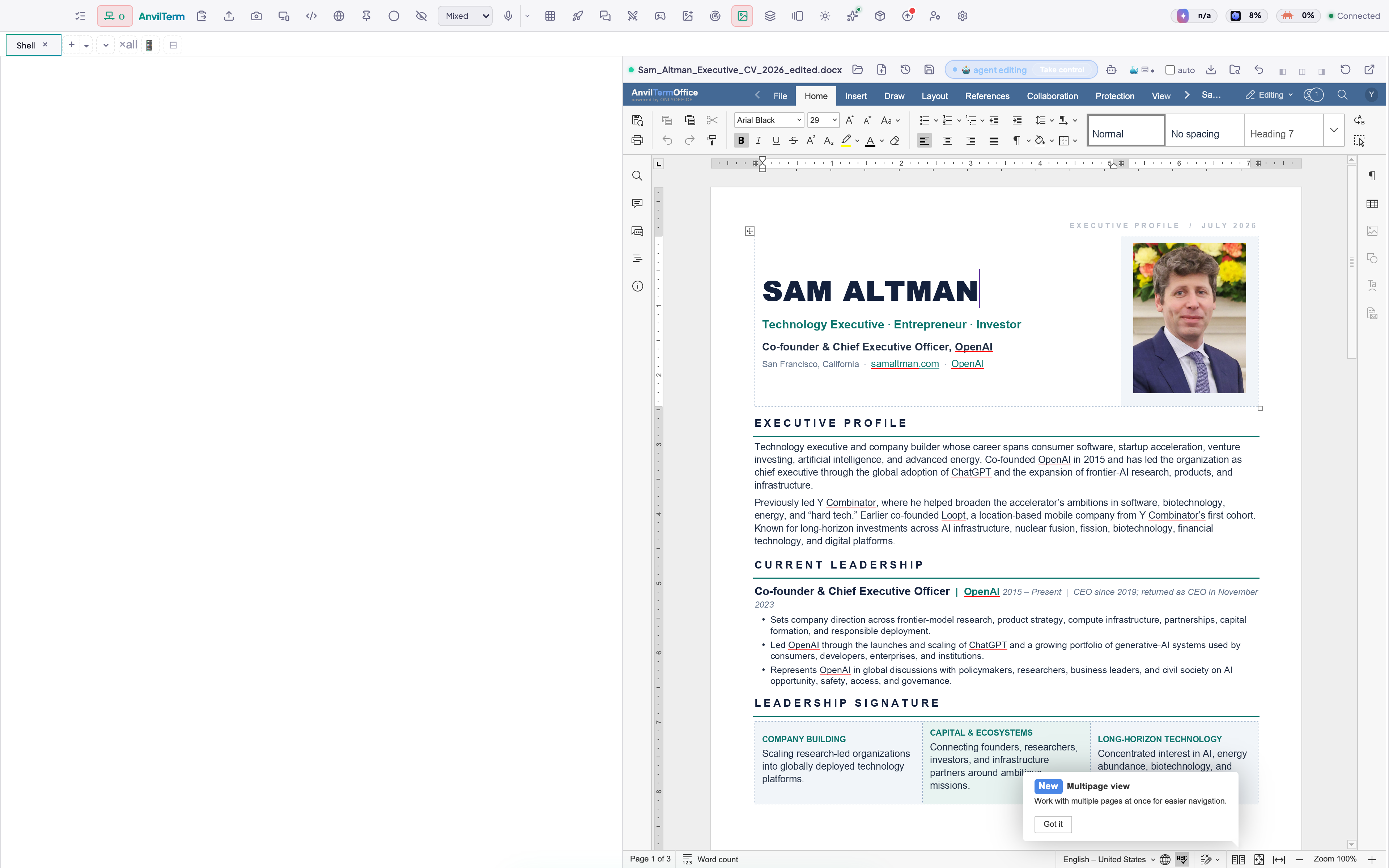
A live Office suite beside your terminal. Agents write real .docx / .pptx / .xlsx —
element by element, styled tables, photos, templates — with every change previewed and
approved by you in a live editor.
Agents drive real, visible browsers — one or forty in parallel. Log in for them, watch every click, export any run as a Playwright script. Stock-watch entire retailer grids while you sleep.
A phone-frame view with touch support and a mobile-tuned document editor — demo your agents in vertical video, or drive them from your couch.
GPT-5.6, Claude, Gemini and Grok come pre-primed: résumé / brochure / proposal / course-deck recipes, photo-to-document replication, live progressive building. Ask for a document — watch it assemble itself.
Mirror and drive iPhones, Android devices and TVs from the same terminal your agents live in. Simulators, real hardware, screenshots straight to the clipboard.
Notarized builds, priority fixes, early features — and customization: your templates, your skills, your workflows baked into the studio.
Invite-first rollout. Drop your email — you'll get the studio build and a hand setting it up.
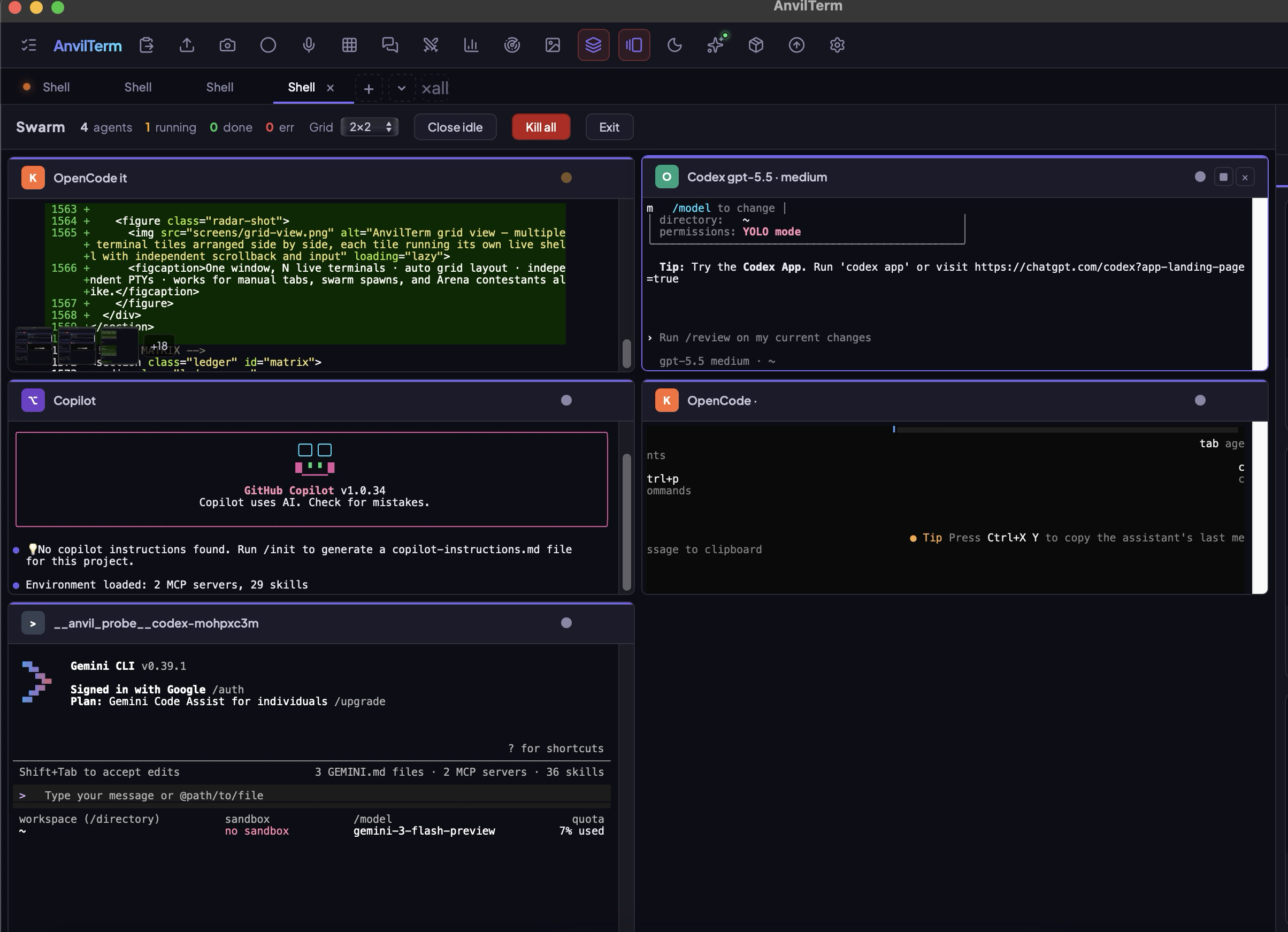
Spawn Claude, Gemini, Codex and OpenCode in one window. They debate in a shared chat, hand off artifacts, cross-check each other's work — while you watch every keystroke live. No Discord. No copy-paste. No tab juggling.
 claude · lead
claude · lead
 gemini
gemini
 codex
codex
 opencode
claude · review
opencode
claude · review
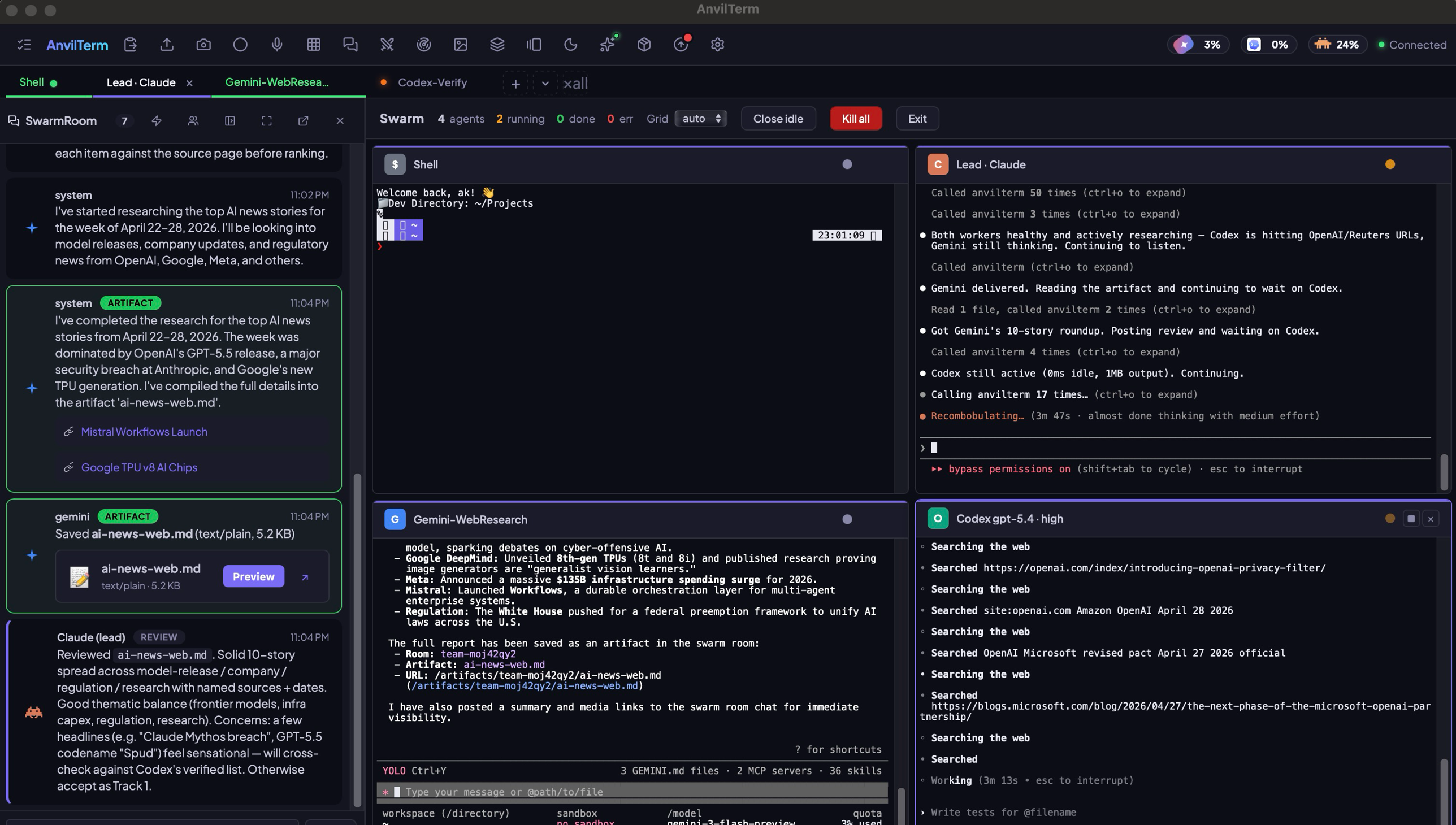
ai-news-web.md
Codex · Verifies every URL live
SwarmRoom · Their group chat, in your terminal
~/.anvil/swarm/. The lead reads what specialists ship and decides what's worth keeping — you just approve the result.
Lead agent delegates subtasks. Specialists pick them up, report back in the same room. You watch the transcript live in a chat tile. Works with any agent that speaks MCP — which is all of them.
Your agents are literal claude, codex, gemini binaries. You see exactly what the TUI sees.
swarm_route(["multimodal"]) → Gemini. ["reasoning"] → Claude. ["refactor"] → Codex.
One agent = one tab. Four = 2×2. Eight = 3×3. Each tile stops, closes, exports on its own.
Spawn a single Claude lead. It reads the prompt, calls swarm_vendors, picks specialists, delegates, merges the result. You just watch and approve. No team-building UI required.
Every tile streams its token counter scraped from the TUI. The toolbar aggregates daily + weekly spend across Claude + Codex + OpenCode. Forecast tells you when you'll hit the cap.
Stop guessing which model is best. Pick two — Claude vs GPT-5.5, Sonnet vs Opus, Gemini vs anyone — paste your prompt, hit Start. Live previews stream side-by-side. Real tokens. Real cost. Real time. You score 1-10 and the winner ships. Save the lab, re-run next month, watch the rankings flip.
Every battle is stored at ~/.anvil/arena/<id>.jsonl. Bring it back six months later, re-run on new model versions, watch the winner flip. Reproducible benchmarking — for the laptop era.
Forge marketplace, Model Radar, Grid view, inline media — every screen designed to keep agents at the center of attention without burying the work they ship.
AnvilTerm ships with a Model Context Protocol server. One command registers it across Claude Code, Codex, Gemini, OpenCode. Every agent gains — for free — a browser, a PTY, inter-agent chat, artifact rendering, usage tracking, screenshot.
# install once, then wire AnvilTerm into every installed agent at once npm install -g anvilterm anvilterm-mcp-install # registers MCP in Claude Code, Codex, Gemini, OpenCode, Copilot anvilterm-doctor # verify every vendor sees the MCP + skill # now from any agent: terminal_create() · terminal_write() · terminal_read() · terminal_screen() terminal_screenshot() · terminal_run() · terminal_list() · terminal_close() tui_type() · tui_interrupt() · tui_choose() · tui_paste_ref() swarm_spawn() · swarm_route() · swarm_vendors() · swarm_check_stuck() swarm_room_post() · swarm_room_listen() · swarm_room_thread() · swarm_room_list() swarm_artifact_save() · arena_push_artifact() · arena_current()
A tab created via MCP appears as a live tile in the AnvilTerm window. You watch — and intervene if needed. Standalone fallback via node-pty if the UI isn't running.
Every MCP-speaking client. Stdio transport. Register once, the toolset travels with you.
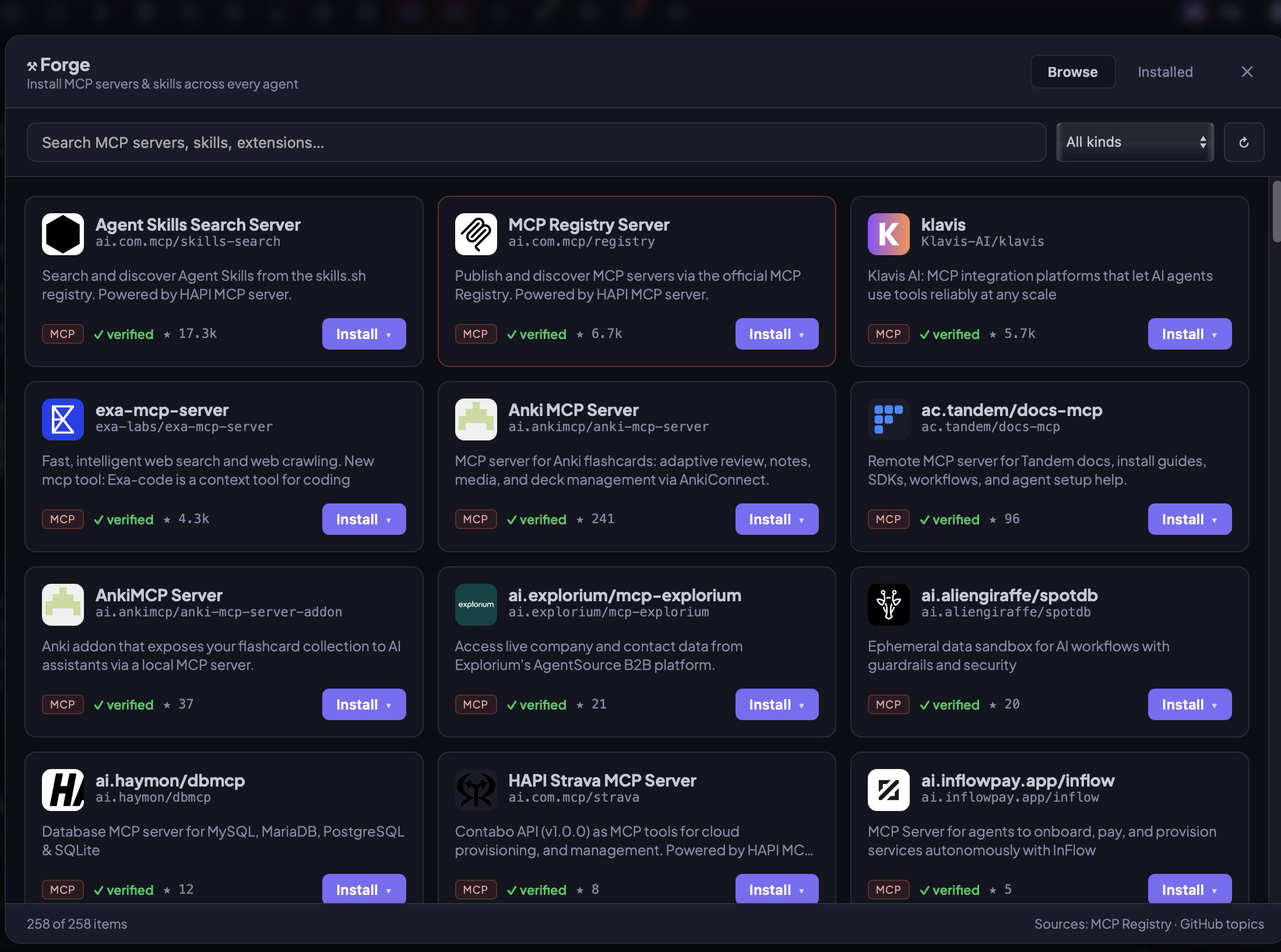
Curated catalog, star-ranked, kind-filtered. Search 258+ servers. Pick one, hit install, choose Claude / Codex / Gemini / OpenCode — or all of them. Forge writes directly to each agent's config with a _forge:true tag so it can manage updates and removal cleanly.

Skills get git-cloned to ~/.anvil/skills/ and symlinked into each agent's skills dir. MCP servers get registered in each vendor's config. Installed view shows per-agent status chips so you always know what's actually wired.
Cmd+K opens an Ollama-backed assistant with native function calling. Gemma 4, Qwen 2.5/3, Llama 3.1, Mistral Nemo. Prompts never leave the machine. Ideal for regulated work, sensitive repos, a plane, a café with no wifi.
Code, prompts, context — none of it leaves your laptop.
Models that speak tools return structured calls that render as one-click run buttons in the chat.
The assistant reads the visible terminal screen so suggestions are grounded in what's actually running.
Claude's built-in subagents are great when one model is enough. A real swarm — Claude + Codex + Gemini + OpenCode running in parallel as live CLIs — wins on parallelism, model diversity and visibility. Here's the honest breakdown on 40 mixed refactor / research / UI tasks.
| Dimension | AnvilTerm Swarm | Claude Subagents |
|---|---|---|
| Parallelism | N real PTYs in parallel | Sequential within parent turn |
| Context window per worker | Full · 1M tokens each · no compaction | Shared parent, compacted on dispatch |
| Model diversity | Claude · Codex · Gemini · OpenCode · Copilot · Ollama | Claude family only |
| Live output | Dedicated live tile per agent | Opaque spinner until result |
| Human-in-the-loop | Type into any tile, paste refs, interrupt | None once dispatched |
| Artifact rendering | Iframes · SVG · markdown · live | Text summary returned to parent |
| Failure isolation | One agent fails, N-1 keep working | Subagent failure blocks parent turn |
| Token cost routing | Per-vendor metered, route cheap tasks to Ollama | All charged against parent's Claude quota |
| Determinism | Fresh PTY state per agent | Inherits parent compaction |
| Tool access | Each agent carries its own MCP toolkit | Parent's MCP toolkit only |
| Reproducibility | Session JSONL + Arena replay | No persistent transcript |
| Best for | Cross-vendor compare, parallel research, long refactors | Tightly-coupled chains in one model family |
Note: wall-clock × is normalized to swarm=1.0 across 40 mixed tasks. Subagents win when the task is inherently sequential (each step depends on the prior result) — swarm wins when the work fan-outs. Use both.
Stop typing /usage three times. AnvilTerm pins your Claude, Codex, and Gemini limits next to your prompt — live, all three at once. No API keys. No OAuth. Just the same numbers your CLI sees, where you actually need them.
Built on a passive scraper, not a side-channel API. AnvilTerm watches the bytes your CLI prints when you run /usage or /status, parses them, and stamps the result on the chip. The first-party numbers, free of provider rate-limits, accurate to the second.
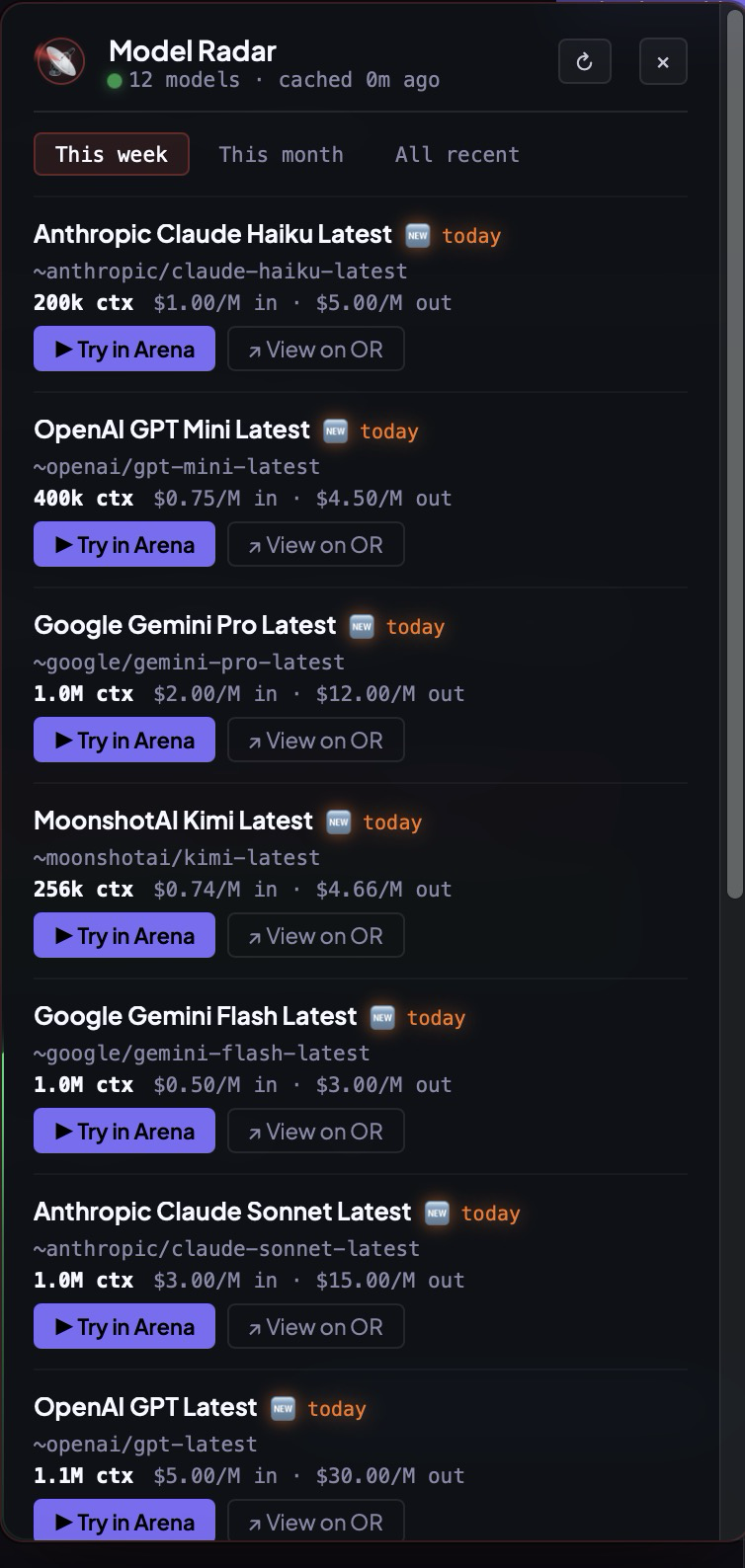
AnvilTerm watches OpenRouter and the major vendor changelogs in the background, deduplicates aliases, and surfaces the freshest checkpoints with context window, input/output pricing, and a one-tap Try in Arena button — head-to-head against your current driver, on your repo, on your prompt. Stop scrolling Twitter to figure out what's actually new. The radar already pinged. The arena is already live.

You'll spend most of the day in this as a regular terminal — so the daily-driver details get the same care as the multi-agent stuff. Find in tab. Search across every tab. Drop a YouTube link, see the thumbnail. Run a Pomodoro. Talk to your agent.
⌘F highlights every match in the active terminal's scrollback. ⇧⌘F searches every tab's last 5,000 lines, groups results by tab, click a hit → switches and scrolls to the line. Five agents running, one search box.
anvil . from any shell opens a new tab at that cwd. App not running? It launches. OSC 7 auto-renames the tab.
Paste a URL or drop a file. Thumbnails inline, waveform player for audio, PDF tiles. Multi-line wrapped URLs handled.
Hold the mic, talk, watch the waveform — your transcript drops into the active agent's prompt the moment you let go. Hands stay on the test. Eyes stay on the code. Cuts a 40-keystroke command to 3 seconds.
Type ship the release 25m → instant timer. Click ▶ Start → everything else dims to 35%. 25m later, audible nudge plus system notification "Is X done?". Not another app to switch to — same window, same flow.
⌘K fuzzy-fires anything: kill all, spawn 4 agents, or natural-language "find the tab where the test failed". 📡 Radar glows when a fresh OpenRouter model drops — one click sends it to Arena. 🌙 cycles dark / light / theme; palette swaps live, no flicker.
Type a file path, drop an image, paste a YouTube link, fetch a PDF — AnvilTerm renders the preview right where the bytes are. Hover any URL or path in the scrollback to peek the file in a floating thumbnail; the side Media rail collects every image, video, audio, and doc this session has touched, with one-tap Path · URL · Copy · Insert actions. Your terminal finally knows what a JPG looks like.
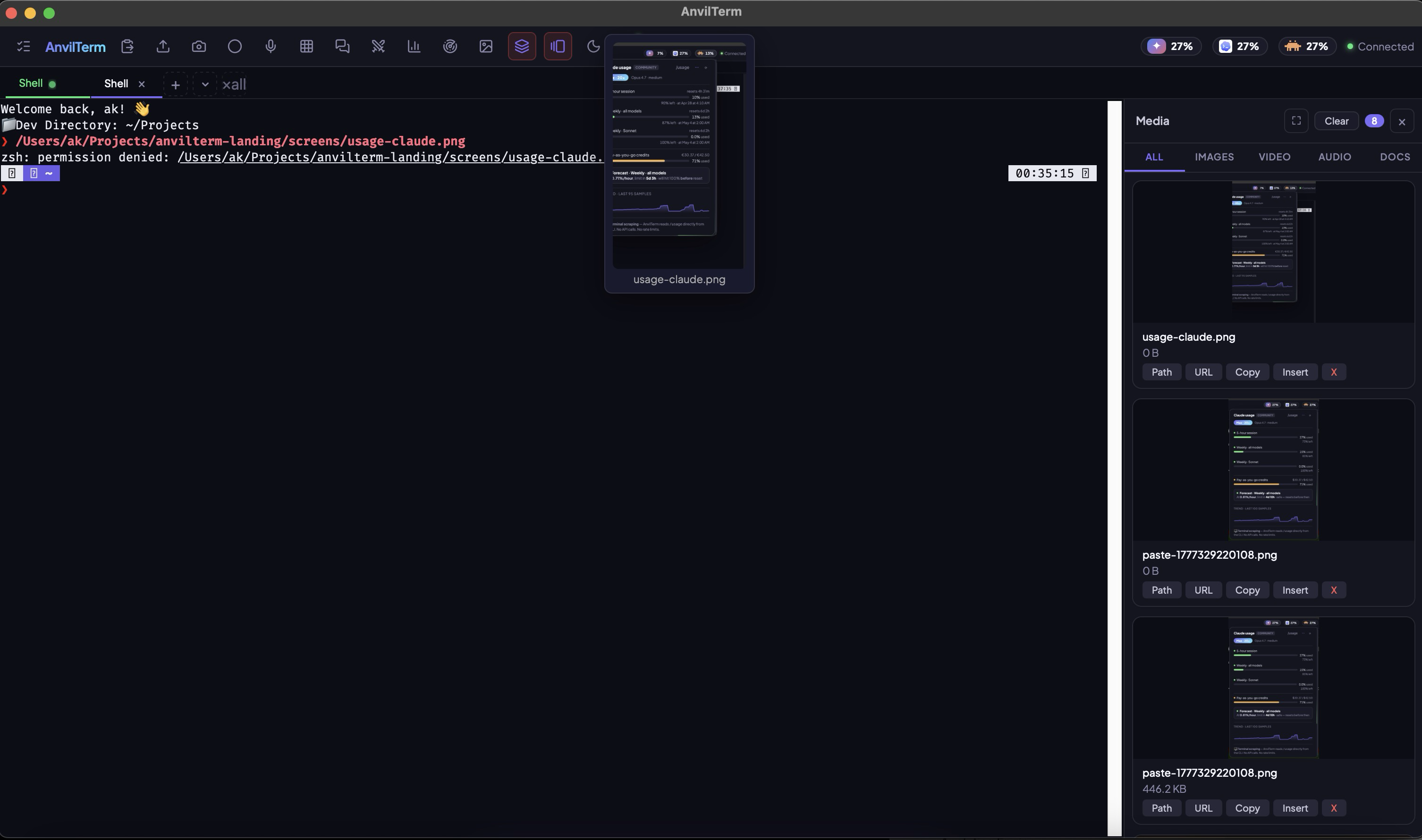
One keystroke arranges every open terminal — manual shells, swarm tiles, Arena contestants — into a live grid. Each tile keeps its own PTY, its own scrollback, its own input. Watch four agents race the same prompt, or just keep an eye on a long build while you work next door. Same window, same window manager, no third-party tile manager required.
A full point-and-click adventure — painterly scenes, per-character AI voices, a verb-coin interface, drag-and-drop puzzles and animated cutscenes — built end-to-end by orchestrating Claude, Codex and Grok inside AnvilTerm. The art and voice acting were generated through the agents, wired together live, and shipped to the web. No game engine, no team — one terminal, many agents.
If a terminal can ship a voiced, animated adventure game, it can ship your side project. Play the demo, then go build your own.
Every other terminal is excellent at its thing. The matrix below is the proof — not marketing. Hover any row to see only AnvilTerm light up.
| Capability | AnvilTerm | Warp | iTerm2 | Ghostty | WezTerm | Kitty | Alacritty | Tabby |
|---|---|---|---|---|---|---|---|---|
| Multi-agent swarm · live tiles | ● | — | — | — | — | — | — | — |
| MCP server · agents drive the terminal | ● | partial | — | — | — | — | — | — |
| SwarmRoom · inter-agent chat | ● | — | — | — | — | — | — | — |
| Arena · head-to-head benchmark | ● | — | — | — | — | — | — | — |
| Forge · MCP + Skills marketplace | ● | catalog | — | — | — | — | — | — |
| Capability routing (task → best model) | ● | — | — | — | — | — | — | — |
| Cross-vendor usage tracking | ● | — | — | — | — | — | — | — |
| Usage forecast · threshold alerts | ● | — | — | — | — | — | — | — |
| Inline images · SVG render | ● | partial | ✓ | — | partial | ✓ | — | — |
| Inline video · PDF · audio waveform | ● | — | — | — | — | — | — | — |
| YouTube embed · hover previews | ● | — | — | — | — | — | — | — |
| Markdown table → spreadsheet | ● | — | — | — | — | — | — | — |
| Local AI · offline assistant | ● | — | plugin | — | — | — | — | — |
| Voice input · push-to-talk | ● | — | — | — | — | — | — | — |
| Session recording · ANSI + plain | ● | partial | — | — | — | — | — | — |
| Interactive screenshot → MCP | ● | — | — | — | — | — | — | — |
| Automation API (DevTools · Playwright) | ● | — | AppleScript | — | Lua | RC | — | plugins |
| Works offline · no cloud lock-in | ● | — | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| Open source | MIT | closed | GPL | MIT | MIT | GPL | Apache | MIT |
| macOS · Linux · Windows | ● ● ● | ✓ ✓ ✓ | mac | ✓ ✓ β | ✓ ✓ ✓ | ✓ ✓ — | ✓ ✓ ✓ | ✓ ✓ ✓ |
| Native GPU renderer | xterm.js | ✓ | Metal | ✓ | ✓ | ✓ | OpenGL | — |
Every AI CLI in one workspace. Benchmark them on real work. Pick the best tool for each job. Never break your flow.
A browser, a PTY, an artifact renderer, image / PDF / YouTube understanding, a room to talk to their siblings. MCP, done for you.
Arena runs head-to-head on real CLIs, real tasks. Every run is a signed receipt — tokens, cost, time, tests passed — appended to ~/.anvil/benchmarks/runs.jsonl. Reproducible by anyone with the same repo and prompt.